Technieken voor het (univariaat) beantwoorden van één variabele
Inhoud:
T-toets op één gemiddelde
Chikwadraattoets voor frequenties van één nominale variabele
Toets op een proportie
Met deze toets ga je na of het gemiddelde van een kwantitatieve variabele afwijkt van een vaste waarde (getal).
Statistische nulhypothese
De nulhypothese is dat het gemiddelde van de populatie waaruit de steekproef getrokken is, gelijk is aan het opgegeven getal.
H0: μ = μ0 waarbij μ0 de waarde van het gemiddelde volgens de nulhypothese is.
Voorwaarden
De numerieke variabele is normaal verdeeld in de populatie waaruit de steekproef getrokken is of de steekproef bevat meer dan 30 paren.
Een eenvoudige maar beperkte controle op normaliteit vind je in de hint Controle op normale verdeling.
Je kunt beter een z-toets uitvoeren wanneer de steekproef minstens 100 waarnemingen bevat of wanneer de numerieke variabele normaal verdeeld is in de populatie en de standaarddeviatie in de populatie is bekend. SPSS voert echter altijd een t-toets uit.
SPSS commando
- Om een 'one sample t-test' uit te voeren kies je: ANALYZE- COMPARE MEANS - ONE SAMPLE T-TEST.
- In het betreffende scherm kun je de interval variabelen selecteren waarvan je de gemiddelden wilt vergelijken met een vaste waarde. Tik achter 'Test Value' de waarde waarmee je de variabele wilt vergelijken.
- Klik op de knop OPTIONS. In het betreffende scherm kun je het betrouwbaarheidsinterval opgeven (de default is 95%). Ook kun je kiezen tussen het listwise of pairwise verwijderen van missende data.
SPSS Output
De belangrijkste output:
De tabel met de beschrijvende statistieken van de variabele waarvan het gemiddelde getoetst wordt. Hier is dit de variabele "Hoe oud bent u?", die een gemiddelde heeft van 36,25 in de steekproef.
One-Sample Statistics
|
N |
Mean |
Std. Deviation |
Std. Error Mean |
|---|
| Hoe oud bent u? |
1551 |
36,25 |
16,041 |
,407 |
|---|
De tabel met de toetsresultaten. Hier wordt als vaste waarde het getal 36,8 gebruikt (achter "Test Value"); dit is de gemiddelde leeftijd van de volwassen Nederlanders in 2006 (volgens de statistieken van het CBS).
De tabel geeft de waarde van de toetsingsgrootheid t, het aantal vrijheidsgraden (onder "df"), de tweezijdige overschrijdingskans (onder "Sig."), het verschil tussen het gemiddelde van de steekproef en de testwaarde (onder "Mean Difference") en de linker en rechter grens van het betrouwbaarheidsinterval voor dit verschil.
LET OP: Je moet deze grenzen optellen bij de waarde van het populatiegemiddelde volgens de nulhypothese om het interval te krijgen waarbinnen het echte populatiegemiddelde met 95% (of een ander percentage) zekerheid valt. In dit voorbeeld is het 95%-betrouwbaarheidsinterval dus [36,8 - 1,35; 36,8 + 0,25] oftewel [35,45, 37,05].
One-Sample Test
|
Test Value = 36.8 |
|---|
| t |
df |
Sig. (2-tailed) |
Mean Difference |
95% Confidence Interval of the Difference |
|---|
| |
|
|
|
Lower |
Upper |
|---|
| Hoe oud bent u? |
-1,342 |
1550 |
,180 |
-,547 |
-1,35 |
,25 |
|---|
Rapportage
Vermeld het volgende:
- Het gemiddelde en de standaarddeviatie van de steekproef en de vaste waarde waartegen het steekproefgemiddelde getoetst wordt. Maak duidelijk wat de variabele en de eenheden zijn.
- De waarde van de toetsingsgrootheid t, het aantal vrijheidsgraden (tussen haakjes, direct achter t) en de precieze overschrijdingskans. Wanneer de toets eenzijdig is, voeg je (eenzijdig) toe. NB de overschrijdingskans wordt altijd met 3 decimalen gerapporteerd.
- Vermeld het betrouwbaarheidsinterval (Confidence Interval, CI) van het gemiddelde.
- Wanneer de toets significant is, vermeld je ook de effectgrootte - Cohen's d - die je met de hand moet uitrekenen op grond van de SPSS output. SPSS berekent d namelijk niet voor je. Interpreteer het effect in termen van klein, middelmatig of groot.
Voorbeeld: "De gemiddelde leeftijd van de respondenten in de steekproef (M = 36,25, SD = 16,04) wijkt niet significant af van de gemiddelde leeftijd van volwassen Nederlanders in 2006 (36,8 jaar), t (1550) = -1,34; p = 0,180, 95%-CI [35,45, 37,05]."
Rekenen voor alle studenten
Reguliere studenten moeten de t-waarde van de steekproef, het steekproefgemiddelde en de standaardfout uit elkaar kunnen afleiden. Ook moeten zij uit de geschatte standaarddeviatie van de variabele (s) en de omvang van de steekproef (N) de standaardfout kunnen berekenen. De relevante formule:
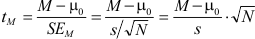
Verder moeten zij in de tabel met kritieke t-waarden kunnen opzoeken of een resultaat significant is op 5% (0,05), 1% (0,01) of 0,1% (0,001).
Ze moeten ook een betrouwbaarheidsinterval kunnen uitrekenen wanneer de standaardfout gegeven is. De formule:
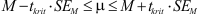
Met de hand moeten studenten een z-toets op één gemiddelde kunnen uitvoeren en een betrouwbaarheidsinterval kunnen berekenen wanneer de standaardfout van het gemiddelde of de standaarddeviatie in de populatie gegeven zijn. Formules:
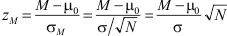
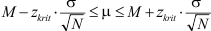
Ook moeten zij de eenzijdige overschrijdingskans kunnen berekenen uit de tweezijdige kans die SPSS geeft: deel de tweezijdige kans door 2 om de eenzijdige kans te krijgen.
Tenslotte moeten ze op grond van SPSS output de effectgrootte kunnen berekenen:
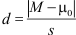 waarin de teller het absolute (dus positieve) verschil is tussen het steekproefgemiddelde en het populatiegemiddelde volgens de nulhypothese (dit verschil staat in de SPSS tabel One-Sample Test onder Mean Difference) en s is de geschatte standaardafwijking in de steekproef (staat in de tabel One-Sample Statistics).
waarin de teller het absolute (dus positieve) verschil is tussen het steekproefgemiddelde en het populatiegemiddelde volgens de nulhypothese (dit verschil staat in de SPSS tabel One-Sample Test onder Mean Difference) en s is de geschatte standaardafwijking in de steekproef (staat in de tabel One-Sample Statistics).
Hier is de effectgrootte |-0,547| / 16,041 = 0,547 / 16,041 = 0,034. Een zwak tot verwaarloosbaar effect. Omdat dit effect niet significant was, is het niet gerapporteerd.
Rekenen voor excellentiegroep
Studenten in de excellentiegroep moeten tevens de t en z-waarde en het betrouwbaarheidsinterval voor een steekproef kunnen uitrekenen op grond van een datamatrix.
Voorwaarden
Bootstrappen mag altijd toegepast worden wanneer de steekproef representatief is voor de populatie. Bij eenvoudige toetsen is dat in de praktijk al voldoende het geval bij een steekproef van enkele tientallen waarnemingen.
SPSS commando
- Voer de handelingen uit om een t-toets op één gemiddelde op te vragen in SPSS.
- Klik op BOOTSTRAP en kies de optie 'Perform bootstrapping'.
- Zet het aantal bootstrapsteekproeven bij voorkeur op 5000.
NB SPSS lijkt het bootstrappen bij elke toets uit te voeren totdat de optie 'Perform bootstrapping' weer wordt uitgezet.
SPSS Output
Naast de gebruikelijke tabellen voor een t-toets worden twee extra tabellen met bootstrapresultaten gegeven.
De eerste tabel geeft het betrouwbaarheidsinterval volgens de bootstrapmethode voor het gemiddelde en de standaarddeviatie van de testvariabele.
De tweede tabel geeft het betrouwbaarheidsinterval voor het gemiddelde verschil (het verschil tussen het steekproefgemiddelde en het populatiegemiddelde volgens de nulhypothese) alsmede een overschrijdingskans voor het gemiddelde verschil dat in de oorspronkelijke steekproef is gevonden. Deze overschrijdingskans is niet altijd te vertrouwen.
Rapportage
Wanneer je de overschrijdingskans of het betrouwbaarheidsinterval van de bootstraptoets rapporteert, voeg je (bootstrap) toe achter de gerapporteerde p-waarde of het betrouwbaarheidsinterval.
Bijvoorbeeld: "De gemiddelde leeftijd van de respondenten in de steekproef (M = 36,25, SD = 16,04) wijkt niet significant af van de gemiddelde leeftijd van volwassen Nederlanders in 2006 (36,8 jaar), t (1550) = -1,34; p = 0,211, 95%-CI [35,33, 37,12] (bootstrap)."
Wanneer de verdeling van een categorische (nominale of ordinale) variabele in de populatie bekend is, kan de chikwadraattoets toegepast worden.
Statistische nulhypothese
De nulhypothese is dan dat de verdeling in de populatie waaruit de steekproef is getrokken niet afwijkt van de verdeling in de bekende populatie:
H0: π1 = πA; π2 = πB; ...; πk = πK waarbij πA de proportie van de eerste categorie in de populatie is (etcetera).
Een bijzonder geval is de situatie waarin alle proporties in de populatie even groot zijn: H0: π1 = π2 = π3 = π4 ... = πk .
Voorwaarden
Maximaal 20% van de categorieën mag een verwachte waarden hebben die lager is dan 5 en geen enkele categorie mag een verwachte waarde onder 1 hebben.
SPSS commando
- Kies het commando ANALYZE-NONPARAMETRIC TESTS-LEGACY DIALOGS-CHI SQUARE.
- Selecteer de categorische variabele waarvan je de verdeling wilt toetsen onder 'Test variable List'.
- Selecteer onder 'Expected Values' de optie 'All categories equal' wanneer je uitgaat van een gelijke verdeling. In alle andere gevallen vul je de verwachte waarden volgens de nulhypothese (bijvoorbeeld absolute aantallen of de percentages in de populatie) een voor een in onder 'Values'. Zorg ervoor dat je de getallen in de volgorde invult waarin de categorieën van de variabele gecodeerd zijn.
- Plak de syntax en laat haar uitvoeren.
Een omslachtiger alternatief (zie boek):
- Kies het commando ANALYZE-NONPARAMETRIC TESTS-ONE SAMPLE, kies Customize Analysis in het Objective tabblad.
NB controleer dan eerst of de variabele in SPSS nominaal of ordinaal meetniveau heeft; met het meetniveau scale kan de toets niet uitgevoerd worden.
- Selecteer de categorische variabele waarvan je de verdeling wilt toetsen onder 'Test Fields' in het Fields tabblad.
- In het tabblad Settings, kies 'Customize tests', vink aan: Compare observed probabilities to hypothesized (Chi-Square test) en onder Options kies je tussen een gelijke verdeling of verwachte waarden die je zelf invult voor alle categorieën. In dit laatste geval moet je voor elke categorie eerste de code (waarde) invullen en vervolgens het percentage dat je voor deze categorie verwacht volgens de nulhypothese. Wanneer je absolute aantallen hebt, moet je die eerst zelf omrekenen naar percentages.
- Plak de syntax en laat haar uitvoeren.
SPSS Output
De belangrijkste output: de tabel met waargenomen en verwachte waarden, en de tabel met de testresultaten.
v3
|
Observed N |
Expected N |
Residual |
|---|
| -1,00 |
5 |
10,5 |
-5,5 |
|---|
| 1,00 |
16 |
10,5 |
5,5 |
|---|
| Total |
21 |
|
|
|---|
Test Statistics
|
v3 |
|---|
| Chi-Square(a) |
5,762 |
|---|
| df |
1 |
|---|
| Asymp. Sig. |
,016 |
|---|
| a 0 cells (,0%) have expected frequencies less than 5. The minimum expected cell frequency is 10,5. |
Rapportage
Vermeld het volgende:
- De waarde van chikwadraat met het aantal vrijheidsgraden en de p-waarde.
Bijvoorbeeld: "De frequenties zijn significant ongelijk, chikwadraat (1) = 5,76, p < 0,05."
- Als er een significant verschil is, zeg dan welke categorieën vaker dan verwacht voorkomen, en welke minder vaak.
Bijvoorbeeld: "De waarde -1 (niet stemmen in 2002, wel in 2006) komt duidelijk minder vaak voor dan verwacht terwijl het omgekeerde (wel stemmen in 2002 maar niet in 2006) duidelijk vaker voorkomt dan verwacht."
- Wanneer de verwachte frequenties niet aan de eis voldoen (hoger dan 1, minstens 80% hoger dan 5), vermeld je alleen dat de chikwadraattoets om deze reden niet toegepast kan worden.
Rekenen voor de excellentiegroep
Voor de handmatige berekening, zie de chikwadraattoets voor kruistabellen.
Bij een dichotome variabele, d.w.z. een variabele met maar twee waarden/categorieën, kan de z-verdeling gebruikt worden om te toetsen of een van beide categorieën met een bepaalde proportie voorkomt in de populatie.
Statistische nulhypothese
De statistische nulhypothese is dat de steekproef getrokken is uit een populatie waarin de groep/categorie voorkomt met de gekozen proportie.
H0: π = π0 waarbij π0 de proportie in de populatie is volgens de nulhypothese.
Voorwaarden
Bij een toets op een proportie mag de z-verdeling gebruikt worden wanneer N ∙ π0 > 5 en N ∙ (1 - π0) > 5. N is hier, zoals gebruikelijk, de steekproefomvang en π0 is de proportie successen in de populatie volgens de nulhypothese.
NB wanneer niet aan deze voorwaarde voldaan is, voert SPSS automatisch een non-parametrische toets uit (de binomiaaltoets, zie Van Peet et al. paragraaf 8.2; geen verplichte stof) die dan wel gebruikt mag worden. Je kunt de resultaten dan op dezelfde manier interpreteren en rapporteren. Kortom, met SPSS mag je de toets altijd uitvoeren.
SPSS commando
NB Om de toets te kunnen uitvoeren moet het meetniveau van de variabele in SPSS gedefinieerd zijn:als nominal of als ordinal. Wanneer de variabele als scale is aangemerkt, kunnen de resultaten verkeerd zijn.
- Kies DATA>DEFINE VARIABLE PROPERTIES om de variabele te controleren. Zet het meetniveau van de variabele naast 'Measurement Level' op NOMINAL of ORDINAL als hier SCALE staat.
Wanneer de variabele als SCALE aangemerkt is, past SPSS (soms ten onrechte) de toetsproportie toe op de laagste categorie die voorkomt.
- Kies het commando ANALYZE-NONPARAMETRIC TESTS-ONE SAMPLE.
- Selecteer in het eerste tabblad (OBJECTIVE) de optie 'Customize analysis'.
- Open het tweede tabblad (FIELDS) en selecteer hier de variabele waarvan je de proportie wilt toetsen onder 'Test Fields'.
NB vaak staan alle variabelen uit het bestand al in de lijst onder 'Test Fields'. Verwijder dan alle variabelen waarvan je de proportie niet wilt toetsen.
- Klik het derde tabblad (SETTINGS) en selecteer 'Customize tests'. Vink de optie 'Binomial Test' aan.
- Klik dan op 'Options' (direct onder 'Customize tests' en vul de proportie volgens de nulhypothese in bij 'Hypothesized proportion' en de code van de testgroep onder 'Success value'.
- Plak de syntax en laat haar uitvoeren.
Let op: bij de toets op een proportie 0,5 wordt altijd tweezijdig getoetst, bij een andere proportie wordt altijd eenzijdig getoetst. De eenzijdige toets is altijd in de waargenomen richting: wanneer de proportie in de steekproef lager is dan de proportie volgens de nulhypothese, wordt linkseenzijdig getoetst; wanneer de proportie in de steekproef hoger is dan de proportie volgens de nulhypothese, wordt rechtseenzijdig getoetst.
SPSS Output
De output: een tabel met de testresultaten.
Hypothesis Test Summary
| |
Null Hypothesis |
Test |
Sig. |
Decision |
| 1 |
The categories defined by Geslacht = (Man) and (Vrouw) occur with probabilities 0,495 and 0,505 |
One-Sample Binomial Test |
,000 |
Reject the null hypothesis. |
| Asymptotic significances are displayed. The significance level is .05. |
Wanneer er als extra voetnoot bij de tabel staat "1Exact significance is displayed for this test." dan is de standaardnormale verdeling niet gebruikt maar de (exacte) binomiaaltoets.
NB wanneer je in de Output Viewer van SPSS dubbelklikt op deze tabel, krijg je ook een staafdiagram te zien en een tabel met onder andere de waarde van de toetsingsgrootheid en de standaardfout. De gestandaardiseerde testwaarde is (ongeveer) de z-waarde die je ook met de hand kunt uitrekenen, althans wanneer er aan de voorwaarden voldaan is om de standaardnormale verdeling te gebruiken. Hier kun je ook zien dat de test een- of tweezijdig is.
| Total N |
11.806 |
| Test Statistic |
5.050,000 |
| Standard Error |
54,325 |
| Standardized Test Statistic |
-14,606 |
| Asymptotic Sig. (1-sided test) |
,000 |
| 1. The alternative hypothesis is that the proportion of records in the success group is less than the hypothesized success probability. |
Rapportage
Vermeld het volgende:
- De p-waarde en de getoetste proportie. Wanneer er eenzijdig getoetst is, wordt dit vermeld. Als de z-waarde bekend is (maar SPSS levert die niet), wordt die ook vermeld.
Bijvoorbeeld: "Mannen maken significant minder dan 49,5% uit van de populatie waaruit de steekproef is getrokken, p < 0,001, eenzijdig."
Wanneer de hypothesen tweezijdig zijn en de toets is eenzijdig of andersom, dan kan de overschrijdingskans alleen uitgerekend worden door verdubbeling of deling wanneer de standaardnormale verdeling oftewel de z-toets gebruikt is. Deze verdeling is namelijk symmetrisch.
Wanneer de (exacte) binomiaaltoets gebruikt wordt, kun je eenzijdige en tweezijdige overschrijdingskansen niet op deze manier in elkaar omzetten.
Rekenen voor alle studenten
Voor steekproeven die aan de voorwaarde voldoen, kunnen studenten de z-score en het betrouwbaarheidsinterval van een steekproefproportie uitrekenen.
De relevante formules:
Toets: 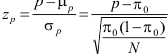
Betrouwbaarheidsinterval: 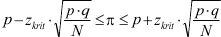 met met q = 1 - p.
met met q = 1 - p.